
- Introduction
- Mechanics
- Pros and Cons
- Case study – Coupons system modernization
- Overcoming challenges and being successful
- Choose thin slices that are “just right”
- Embrace and manage scope changes
- Pick optimal production release granularity
- Establish a continuously improving test loop
- Test responsibly (not only) in production
- Mature your CI/CD practices
- Embrace the need for data synchronization
- Ensure robust observability apparatus is in place
- Be proactive with communication and change management
- Conclusion
Introduction
The journey of modernizing legacy systems can often feel like navigating through a dense forest of old, entangled roots and branches, with a quest to reach the sunlit canopy of modern, efficient, and scalable technology. Conventionally, some organizations may consider a ‘Big Bang’ approach—completely replacing the old system with a new one in one fell swoop. However, the Big Bang approach can be akin to chopping down the entire forest and starting anew—an approach that is fraught with risk, disruption, and often, an immense strain on resources. It’s no surprise then, that it’s relatively uncommon for organizations to adopt this method for significant system overhauls.
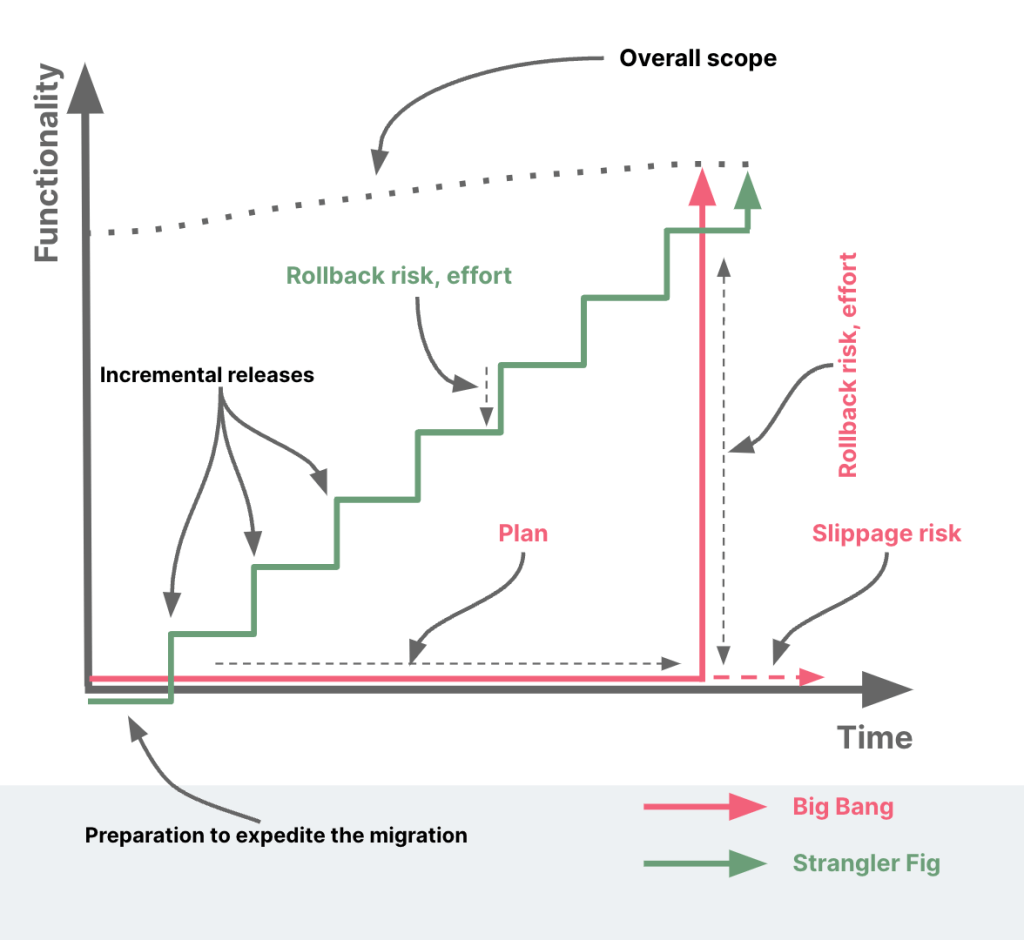
In search of a more manageable alternative, many organizations are turning towards a pattern inspired by nature—the Strangler Fig pattern. This approach, named after the Strangler Fig tree (coined by Martin Fowler) gradually envelops a host tree, represents a gentler, iterative process. Just as the Strangler Fig grows over time, replacing the host from within, this approach involves building a new system around the edges of the old, gradually replacing it piece by piece.
In this article, we explore the Strangler Fig pattern—a viable alternative to the Big Bang approach. We delve into its principles, how it mitigates risk, and how it can be leveraged to effectively modernize legacy systems, ensuring that organizations can reach the sunlit canopy of technological advancement without having to clear the forest.
Mechanics
Conceptually, here is how it works, step by step:
- Identify the System Boundaries: Start by identifying the boundaries of the existing system that you want to replace. This could be an entire application or a smaller subsystem within a larger application.
- Define Thin Slices: Break down the system into manageable parts or “thin slices,” which are small enough to be replaced incrementally but significant enough to deliver business value. These slices should be independent and self-contained where possible.
- Develop New Components: For each slice, develop a new component that replicates the functionality of the old one but with modern technologies and practices. It may also be required to augment this component with additional functionality.
- Route Traffic: Once a new component is ready, implement an indirection layer to route traffic to it instead of the old component. This could be a simple switch or a more complex routing mechanism, depending on the nature of the system.
- Retire Old Components: As new components take over, the old components they replace become redundant and can be retired. This process continues until all components of the old system have been replaced and the entire system can be decommissioned.
- Iterate: The Strangler Fig approach is iterative, meaning you repeat the process of developing new components, rerouting traffic, and retiring old components until the entire system has been migrated.
Conceptually, the process looks like the visual depicted here:
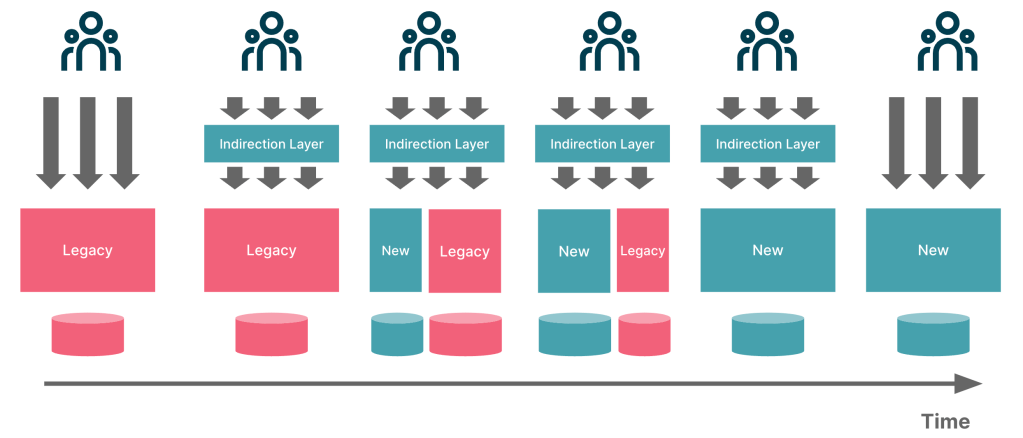
By gradually replacing the old system, the Strangler Fig approach reduces the risks associated with system migration, minimizes disruption, and allows for continuous delivery of value throughout the process.
Pros and Cons
This approach offers several advantages when it comes to replacing legacy systems, especially those that are large, complex, and critical to ongoing operations:
- Incremental Change: The Strangler Fig pattern allows for gradual replacement of the old system, which can reduce risk and make the process more manageable.
- Continuous Operation: Because the system is replaced piece by piece, the legacy system can continue to operate during the transition. This allows for business continuity and minimizes disruption.
- Reduced Risk: By breaking the replacement process into smaller, incremental changes, the risk associated with each change is reduced. If an issue arises, it can be easier to diagnose and rectify because it’s confined to a smaller part of the system.
- Flexibility: The incremental nature of the Strangler Fig pattern also allows for flexibility. If business needs change or if a certain approach isn’t working, it’s easier to change direction without losing a large amount of work.
- Learning and Improvement: Working incrementally allows the team to learn from each step, refine their approach, and improve over time. This can lead to a better final result.
- Phased Allocation: Since the new system is built incrementally, budget, people and resources can be allocated in phases. This can be more manageable than allocating them for a complete overhaul.
While the Strangler Fig approach has many benefits, it can also present certain challenges or become problematic in some scenarios:
- Complex Interdependencies: Legacy systems often have complex, deeply embedded interdependencies. Trying to untangle these to replace one piece at a time can be very challenging.
- Long Transition Period: The Strangler Fig approach is incremental and can therefore extend the transition period. This could lead to prolonged costs and potential complexities in managing two systems simultaneously.
- People Allocation: Balancing people and resources between supporting the legacy system and developing the new system can be difficult. It may also be challenging to find or train personnel to work with both the old and new technologies.
- Incomplete Migration: There’s a risk that due to changing business priorities or other issues, the process stalls before the legacy system is fully replaced. This can result in a hybrid system, which may be more complex and harder to maintain than either a full legacy or a fully modernized system.
- Resistance to Change: Like any significant change, there can be resistance from users or stakeholders, which can slow down or complicate the process.
- Data Synchronization: During the transition period, the same data may need to be kept up-to-date in both the legacy and new system, which can be complex and error-prone.
Case study – Coupons system modernization
We have included a relatively simple case study here, keeping in mind the length of the article. If you are interested in learning about a more complex case study, please check out my talk titled Distributed Event-Driven Services from the trenches at the O’Reilly Software Architecture Conference,
For grocery retailers, coupons functionality plays a pivotal role in several aspects of the business. Coupons serve as a key marketing tool, helping to attract new customers, retain existing ones, and drive sales of specific products. They can stimulate increased purchasing volume and encourage consumers to try new or less popular items. Additionally, coupons can also aid in inventory management, helping to clear out stock before it expires or becomes obsolete. Therefore, having a robust and efficient system for managing coupons is critical.
The coupon management system at this large grocery retailer we were working with, was plagued with a variety of issues. These included inaccurate validations that led to unauthorized discounts, a lack of scalability that resulted in system overloads during peak periods, and inflexible rules that obstructed the creation of custom offers. Furthermore, poor integration with other systems resulted in inconsistent data, and an absence of analytics missed potential insights into effective marketing strategies. Despite these issues, the legacy coupon management system continued to be heavily relied upon. Its critical role in driving sales and managing customer relationships meant that it remained a significant part of the retailer’s operations, underscoring the urgent need for system improvement and modernization.
At a high level, the legacy implementation provided 4 RPC-style endpoints that suffered from a number of issues:
| Endpoint | Functionality | Issues |
|---|---|---|
/get_coupons | Fetches all coupons. Used by default and for unauthenticated users. |
|
/clip_coupon | Allows a user to clip a coupon. |
|
/unclip_coupon | Allows a user to unclip a coupon.> | |
/get_my_coupons | Get coupons clipped by a specific user. |
To make matters worse, the legacy system had little to no documentation and automated tests, making it quite challenging to make even the minutest of changes. To minimize risk, we decided to take an iterative approach. We outline some of the key decisions here:
- Building a solid foundation of understanding: To ensure a successful system transition, the team prioritized building a thorough understanding of the existing system’s functionality. This involved multiple discussions with Subject Matter Experts (SMEs) and creating automated functional tests to treat the system as a black box. These tests provided valuable insights into the system’s behavior. Additionally, automated performance tests were developed to understand non-functional requirements in detail. Log statements were strategically introduced into critical areas using aspect-oriented programming11, creating a centralized logging module. This low-risk approach allowed for seamless integration without altering the legacy codebase. The team gained valuable insights into the system’s inner workings, making informed decisions during the implementation of the new solution and solidifying the transition’s success.
- Picking the first slice: It was now time to pick that all important first thin slice. We chose the /get_coupons functionality because it was heavily used and at the same time, was not as complex as the other pieces. This approach allowed us to strike a balance between addressing pressing needs and ensuring a smooth modernization process, setting the stage for future enhancements while delivering incremental value to stakeholders.
- Building the first slice: We now built out our first component making use of a plethora of sensible defaults for planning, architecture, development, testing, deployment, etc. We also built a simple API gateway component that acted as a passthrough to the legacy system for all requests except the /get_coupons API. The API gateway had some minor transformation logic to retain backwards compatibility with existing clients. For newer clients, the GET /coupons API was RESTful, paginated, allowed clients to choose the outputs they needed, was comfortably way more performant, was well documented, was test-driven and came with several other improvements.
- Ensuring client adoption: To promote timely client adoption during the thin slice development, we prioritized client engagement and user satisfaction. Transparent communication was maintained, keeping clients informed of the rationale, benefits, and timeline of the migration. By addressing specific pain points and incorporating client feedback, we tailored the thin slices to their needs, driving higher adoption rates. We provided awareness sessions and responsive support to ensure clients felt confident in using the new features. Additionally, we shared success stories from other clients who embraced the changes, inspiring confidence in the transition. Collaborative decision-making allowed clients to feel valued and empowered, fostering ownership and commitment to the new system.
- Managing stakeholders: We placed a high priority on clear communications and effective stakeholder management to ensure success. We established regular communication channels, tailored information for different stakeholders, and addressed concerns proactively. Stakeholder engagement was emphasized through regular demos of incremental functionality, involving them in decision-making and managing expectations. The collaborative and transparent approach enabled us to navigate challenges and deliver successfully.
As we proceeded to migrate more complex APIs, several challenges manifested themselves. This ranged from data synchronization, integration complexity, versioning compatibility, error handling and rollback to name a few. We discuss these and other challenges and how to overcome them in the upcoming section.
Overcoming challenges and being successful
Overcoming challenges associated with the Strangler Fig approach requires meticulous planning, clear communication, and a deep understanding of both the old and new systems. Prioritizing critical functionality helps focus efforts, while short iterations allow for flexibility and rapid response to changing needs. Leveraging technology, such as automated testing and robust observability tools, ensures high-quality output and provides valuable insights. Ultimately, a collaborative environment and a strong change management strategy are paramount to aligning all stakeholders and facilitating a successful, smooth transition. Presented below is an assorted catalog of key points to maximize your chances of success:
Choose thin slices that are “just right”
In the Strangler Fig approach to system migration, finding the “Goldilocks’ zone” of complexity and value in the components selected for replacement is crucial. Components that are too simple might offer limited learning and impact, while overly complex components could risk prolonging the process, increasing errors, and discouraging the team and stakeholders alike. Similarly, components of low value may not justify the replacement effort, whereas high-value components, although beneficial, could cause disruption if replacement goes awry.
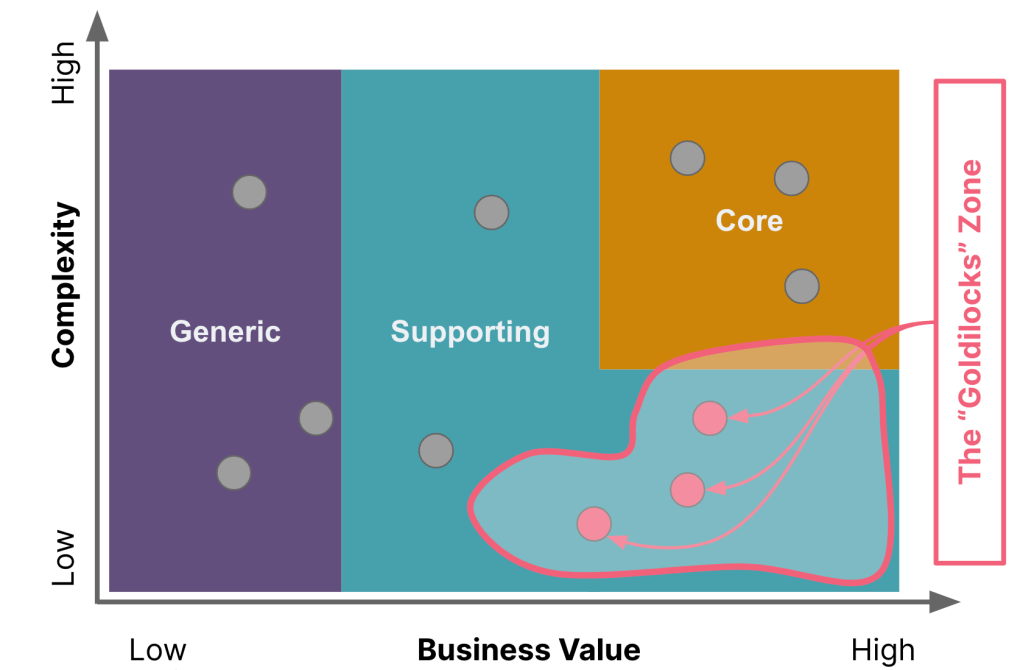
In addition to complexity and business value, several other factors like functional dependencies, technical debt, stakeholder priorities, regulatory compliance, skills availability, risk, alignment with long term strategy, etc. to name a few may need to be considered. Employing a scorecard where features are ranked against these criteria can go a long way towards promoting transparency and objectivity to the exercise. A simple matrix depicted a sample set of criteria is depicted here:

Identifying components that strike a balance between manageable complexity and significant value, especially at the outset, ensures a more effective and beneficial migration. Achieving this balance necessitates a thorough understanding of the system, the business context, and careful planning and prioritization. Applying the principles of domain-driven design and breaking down functionality into coherent bounded contexts become all the more important when making these choices.
Embrace and manage scope changes
Implementing the Strangler Fig approach while meeting ongoing business needs can be a balancing act akin to “changing the wheels while the train is moving.” It is crucial to acknowledge that changing requirements and scope are inevitable and need to be managed effectively. Here are some key techniques:
- Prioritizing Critical Functionality: Concentrate on the most valuable system components first to deliver significant value early on.
- Short Iterations: Use brief development cycles to regularly deliver new functionality, offering the flexibility to accommodate changing business priorities.
- Feature Flags (Toggles): Develop and release new features without system disruption, providing the agility to respond to changing requirements.
- Close Collaboration: Regular communication with business stakeholders ensures a mutual understanding of changing needs, expectations, and priority shifts.
- Dual Track Development: Having separate teams focused on new system development and existing system enhancement allows for a balanced response to emergent business needs.
- Restrict enhancements in the legacy system: Managing enhancements in the legacy system is crucial during modernization, as excessive changes can add complexity and extend the migration timeline. By controlling and prioritizing these enhancements, a smoother and more efficient transition to the new system can be ensured.
- Automated Testing and Deployment: Automating these processes reduces error risk, optimizes development time, and supports a dynamic development environment.
- Robust Backlog Management: Maintaining an up-to-date backlog enables effective planning, prioritization, and accommodation of evolving requirements.
In the face of inevitable changes, these techniques provide a structured approach to balance system modernization with the delivery of new features and enhancements, ensuring a seamless transition during the modernization process.
Pick optimal production release granularity
Deploying thin slices to production is beneficial as it allows for early user feedback, reduces risk due to the smaller scope of each deployment, delivers value to the business promptly, and offers opportunities to learn and improve both the system and deployment processes. The granularity of thin slices plays a crucial role in both test and production environments. In a test environment, you may work with very granular, individual slices. This allows for focused development, testing, and rapid feedback on small portions of the system, reducing risk, and providing learning opportunities. When deploying to production, the strategy may shift. To ensure a coherent user experience and minimize disruptions, it can be beneficial to group related thin slices together before deployment. These groupings typically represent a complete piece of business functionality or a logically related set of features, delivering prompt value to the business.
This approach enables early user feedback and opportunities to learn and improve both the system and deployment processes. However, it also necessitates robust processes for deployment, testing, and managing co-existence and data synchronization between the old and new systems. Thus, careful planning and coordination are vital in deciding the granularity of slices, grouping them for release, and successfully deploying them in a production environment.
Establish a continuously improving test loop
Navigating the labyrinth of legacy systems can pose significant challenges, particularly when it comes to changes or reimplementations of critical functionalities that lack robust testing. An effective strategy to mitigate this risk and prevent regressions involves creating a black box, short-lived suite of functional tests (my colleague Vanessa Towers calls them a parity suite) for a carefully chosen segment of the system.
Upon reliable verification of the legacy system’s behavior, a new implementation is developed. This implementation, while equivalent from an external perspective, benefits from an internally enhanced design, ideally derived from test-driven principles. This strategy simultaneously ensures a suite of fast-running unit tests for regression and maintains the original functional tests.
To further bolster the process, these tests can be integrated into a continuous integration pipeline. Ratcheting on a set of key fitness functions, such as code coverage, cyclomatic complexity, the number of test assertions, Lack of Cohesion in Methods (LCOM4), etc. provides timely, qualitative feedback on the system’s health. Incorporating the practice of mutation testing offers valuable insights into the quality of the written tests, contributing to a disciplined and thorough process.
Functional tests are then applied to the new implementation, to ensure that the original functionality is preserved. After the test suite certifies the new implementation, it seamlessly replaces the original functionality, maintaining the end user’s experience. Once validated, the ephemeral functional suite can be significantly reduced, retaining only the most valuable scenarios. Conceptually, this process looks like how it is depicted in this visual:
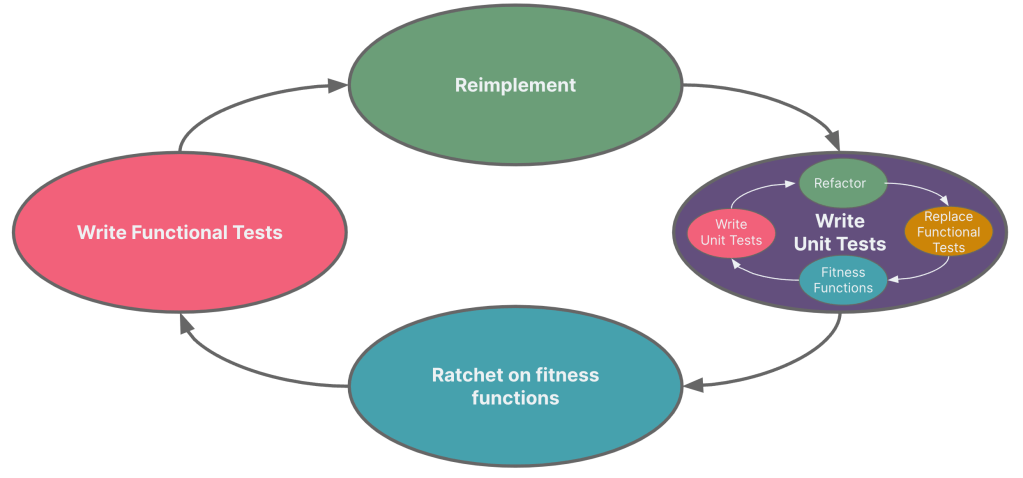
This systematic, risk-managed approach, enhanced by continuous integration and metric monitoring, can be replicated to modernize additional parts of the legacy system, optimizing the chances of successful transformation.
Test responsibly (not only) in production
“I don’t always test my code, but when I do, I test in production” or so goes the infamous meme. While there can be no substitute to a sound testing strategy, testing safely in production is a powerful strategy that allows teams to validate changes and catch issues in the environment where the software will actually be used. However, it’s crucial to approach testing in production responsibly to avoid disruptions and ensure a high-quality user experience. Several techniques enable safe and effective testing in production, particularly in the context of the Strangler Fig approach to system migration:
- Feature Flags (Toggles): In addition to helping with managing scope (as mentioned in the section above), feature flags also provide the flexibility to manage the exposure of new components based on their readiness and performance. By selectively enabling or disabling components in the live environment, teams can control risk while gathering real-world feedback.
- Canary Releases: Canary releases work well with incremental approaches like Strangler Fig. As each slice of the system is replaced, the new component can be initially exposed to a small subset of users, with exposure progressively increased as confidence grows.
- Dark Launches: Dark launching allows new components to be introduced and tested in the production environment without being visible to users. This aligns with the Strangler Fig approach by allowing new components to be tested with real production traffic before they fully replace the legacy system.
- A/B Testing: A/B testing can be used to compare the performance and user experience of the legacy system and the new system. By directing some users to the new components and others to the legacy system, valuable feedback can be gathered to inform the migration process.
Each of these techniques provides a way to manage risk, gather real-world feedback, and maintain a high-quality user experience throughout the migration process.
Mature your CI/CD practices
Robust Continuous Integration/Continuous Deployment (CI/CD) practices are crucial in successfully implementing the Strangler Fig approach. CI/CD pipelines facilitate the automation of integrating changes, running tests, and deploying to production. This automation is well-aligned with the incremental and iterative nature of the Strangler Fig strategy.
- Frequent Integrations: The Strangler Fig approach involves numerous, small changes. CI practices support regular integration of these changes, helping detect and resolve integration issues promptly when they’re less costly to fix.
- Automated Testing: CI pipelines automatically trigger a range of tests with every integration. This ensures each change is validated for functionality, performance, and security – critical when different system parts are at various migration stages.
- Consistent Deployments: CD practices offer consistency and repeatability in the deployment process, reducing error likelihood. This is particularly important when managing both a legacy system and a new system.
- Rapid Feedback: CI/CD provides quick feedback on every change, essential for the iterative nature of the Strangler Fig approach. This allows teams to respond to issues quickly, make improvements, and deliver better quality software.
- Version Control: Well-established CI/CD practices involve strong version control, ensuring all changes are tracked. This is crucial when managing the coexistence of old and new systems.
- Rollbacks: If issues arise, well-structured CI/CD pipelines allow for quick rollbacks, minimizing disruption to users and the business.
Adopting robust CI/CD practices isn’t just a technical requirement, but also a cultural one. It necessitates a commitment to frequent, incremental changes; shared responsibility for quality and reliability; and an investment in automation and tooling. This level of sophistication in CI/CD practices helps ensure a smooth and successful Strangler Fig migration.
Embrace the need for data synchronization
Running both old and new systems side by side, a characteristic of the Strangler Fig approach, necessitates data synchronization, which presents challenges such as ensuring data consistency and integrity, managing performance impacts, and navigating the complexity of transforming data formats or handling different database technologies.
To effectively manage these challenges, robust data synchronization tools are needed, along with failover and recovery mechanisms, performance optimization, monitoring and alerting systems, and thorough testing.
However, it’s also crucial to minimize the need for two-way data synchronization, which can be complex and error-prone. This can be achieved by carefully choosing thin slice use cases for migration, aiming for those that are relatively independent and self-contained. This strategy allows for predominantly unidirectional data flow—from the old system to the new system—avoiding the need for changes in the new system to be reflected back into the old one.
For instance, if you’re migrating an e-commerce platform and you start with the product review functionality, all new reviews could be written directly to the new system, while the old system is updated to read reviews from the new system. This approach simplifies synchronization, reduces potential conflicts, and requires careful planning and a comprehensive understanding of the system and its data dependencies.
As the migration progresses and more functionality moves to the new system, the need for synchronization will gradually decrease until the old system can be fully decommissioned. This holistic approach to data synchronization is key to a successful migration.
Ensure robust observability apparatus is in place
The Strangler Fig approach to system migration is fundamentally an incremental process, involving the gradual replacement of parts of a system while the whole continues to function. This approach requires that the teams involved have a deep and detailed understanding of the system at all stages of the process. This is where having a world-class observability apparatus comes into play.
Observability, in the context of system migration, means having visibility into how the system’s components interact and perform, both individually and collectively. This includes metrics (quantitative data like response times or error rates), logs (records of events that have occurred within the system), and traces (information about the path that a transaction or workflow takes through the system).
An effective observability apparatus provides several critical capabilities:
- Error Detection and Diagnosis: It allows teams to quickly detect and diagnose issues, which is especially important when introducing new components that need to coexist with legacy components.
- Performance Monitoring: It gives teams insight into the performance of both the old and new components, helping them ensure that the new system can meet or exceed the performance of the old system.
- User Experience Monitoring: Observability tools can provide valuable insights into how users are interacting with the system, helping teams understand the impact of changes on the user experience.
- Data-driven Decision Making: Observability provides the data needed to make informed decisions about the migration process, such as prioritizing which components to replace next.
- Confidence in Deployment: With high observability, teams can confidently deploy new components, knowing that they can quickly detect and address any issues that arise.
Having world-class observability apparatus is key to successfully pulling off a migration using the Strangler Fig approach. It allows teams to keep a close eye on the system’s health, performance, and usage as they gradually replace its components, providing the insights and confidence needed to manage the process effectively.
Be proactive with communication and change management
Last but not the least, effective communication and change management are vital for the success of the Strangler Fig approach. Stakeholder buy-in, secured through clear communication, is necessary to drive the significant shift in development and operational processes. It’s essential to keep everyone aligned and informed during this period of incremental change, managing expectations about the gradual realization of benefits. Additionally, as the approach often leads to changes in workflows and roles, efficient change management techniques are needed to ensure smooth transitions. Finally, fostering an open dialogue about successes and challenges allows for continuous learning and improvement, enhancing the process as it progresses. Thus, the Strangler Fig approach, while technically focused, greatly depends on human factors for its success.
Conclusion
As we journey through the dense undergrowth of legacy systems towards the clear canopy of technological innovation, the Strangler Fig approach shines a light on a path that is both pragmatic and effective. It allows organizations to delicately unfurl the tendrils of modernization, weaving them into the old system in an incremental manner, thereby reducing risk and minimizing disruption.
The journey, though, is not without its challenges. It requires the navigator to master several guiding principles and practices. Choosing the “just right” thin slices sets the pace of the journey, while the ability to embrace and manage scope changes defines its flexibility. The selection of optimal granularity for production releases further refines the path, adding precision to each step.
Alongside these strategic decisions, operational considerations also come into play. Testing responsibly in production, maturing CI/CD practices, and embracing the need for data synchronization act as safeguards, ensuring the journey proceeds smoothly even as the landscape changes.
Above all, the journey through the Strangler Fig approach is one of constant observation and communication. The establishment of a robust observability apparatus provides the vision to navigate through complex terrains, and proactive communication and change management practices ensure the entire team marches in unison, aligned towards the shared goal.
In conclusion, while the Strangler Fig pattern presents its unique set of challenges, it offers a manageable approach to system modernization. It’s a path that, with the right strategies and tools, guides organizations safely and surely from the depths of legacy systems into the bright daylight of technological advancement.
- For more details, refer to the section on Logging in chapter 12 of our book. ↩︎
